Constrained Dominant Sets · Graph Selection
Constrained Dominant Sets for Multimodal Document Question Answering
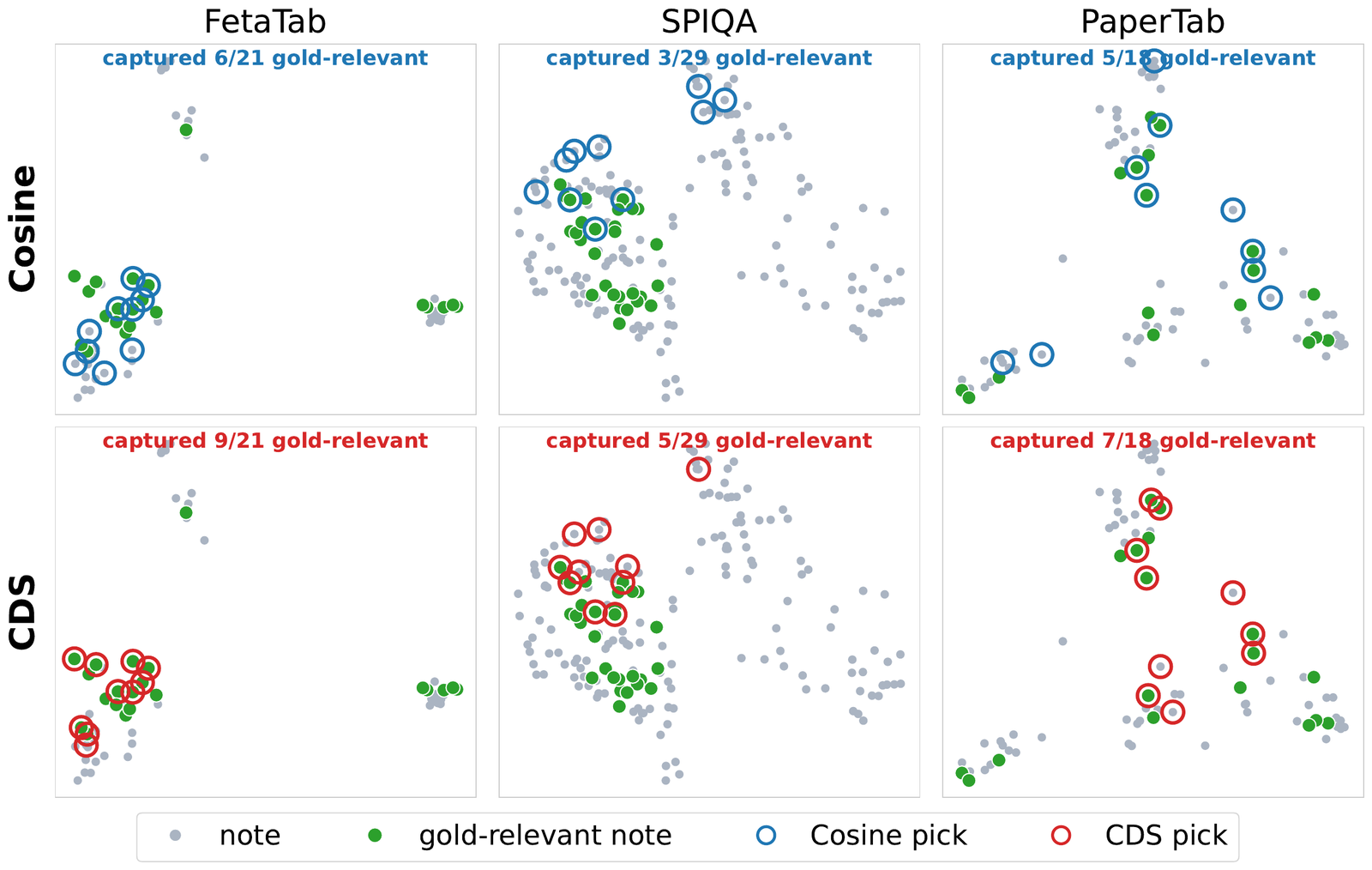
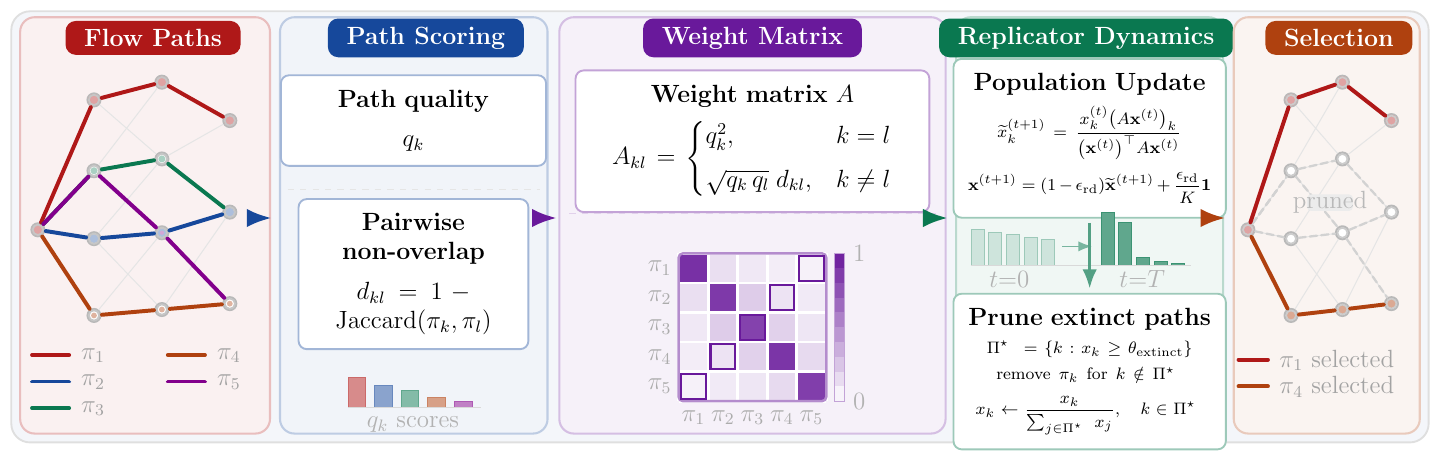
Evidence selection reframed as a constrained dominant-set problem on a query-augmented affinity graph. The query becomes a hard structural constraint; relevance and redundancy balance automatically via a spectral bound — no tuning, no training.
66.99VisDoMBench Avg · SOTA
+37.1over no-retrieval
+4.8MMLongBench-Doc