§ Abstract
Long multimodal document question answering is limited by which evidence reaches the reader, rather than by the quantity retrieved. In lengthy documents, findings recur across figures, captions, and introductory sentences, causing similarity-based retrievers to allocate resources to near-duplicates while overlooking complementary evidence. We introduce a retriever that selects evidence as a Constrained Dominant Set (CDS) on a query-augmented affinity graph. First, the query is encoded as a hard structural constraint, ensuring every selected element connects to the question through the cluster anchor. Second, the relevance–redundancy balance is set automatically by a spectral bound, eliminating manually tuned trade-offs. Third, selection reaches a global equilibrium via replicator dynamics, avoiding greedy distortions. The method is graph-based and requires no training. With a Qwen3-VL-32B reader, CDS sets a new state of the art on VisDoMBench (66.99 average) and improves over the no-retrieval baseline by 37.1 points on VisDoMBench and 4.8 on MMLongBench-Doc.
01 The problem with similarity ranking
On MMLongBench-Doc — 135 PDFs averaging 47.5 pages — even GPT-4o reaches only 44.9 F1. Evidence in the middle of a long context is systematically under-used (the U-shaped attention curve). The principal limitation is therefore not the quantity of accessible information but the selection process.
Most multimodal RAG systems return a flat top-B list ranked by query–candidate similarity. For a question about a chart, such a retriever often returns the figure, its caption, the introductory sentence, and the paragraph restating the finding — spending multiple slots on a single fact. Long documents are deliberately structured to restate findings across modalities, and similarity ranking amplifies this engineered redundancy. Classical fixes (MMR, DPPs) remain heuristic and, crucially, never enforce coherence between the selected set and the query: the query is only a scoring feature, never a constraint.
02 Evidence selection as a constrained dominant set
We reformulate evidence selection as a constrained dominant-set problem on a query-augmented affinity graph. Dominant sets generalise maximal cliques as strict local maxima of a quadratic program on the simplex; the constrained variant additionally requires the cluster to contain a specified seed. Here the query is that seed. Query–note edges encode similarity (relevance); note–note edges encode dissimilarity (diversity). Solving with replicator dynamics yields a soft membership vector whose support is a cluster anchored on the query — high mutual relevance, low mutual redundancy — with no hyperparameter tuning, kernel design, or greedy locking.
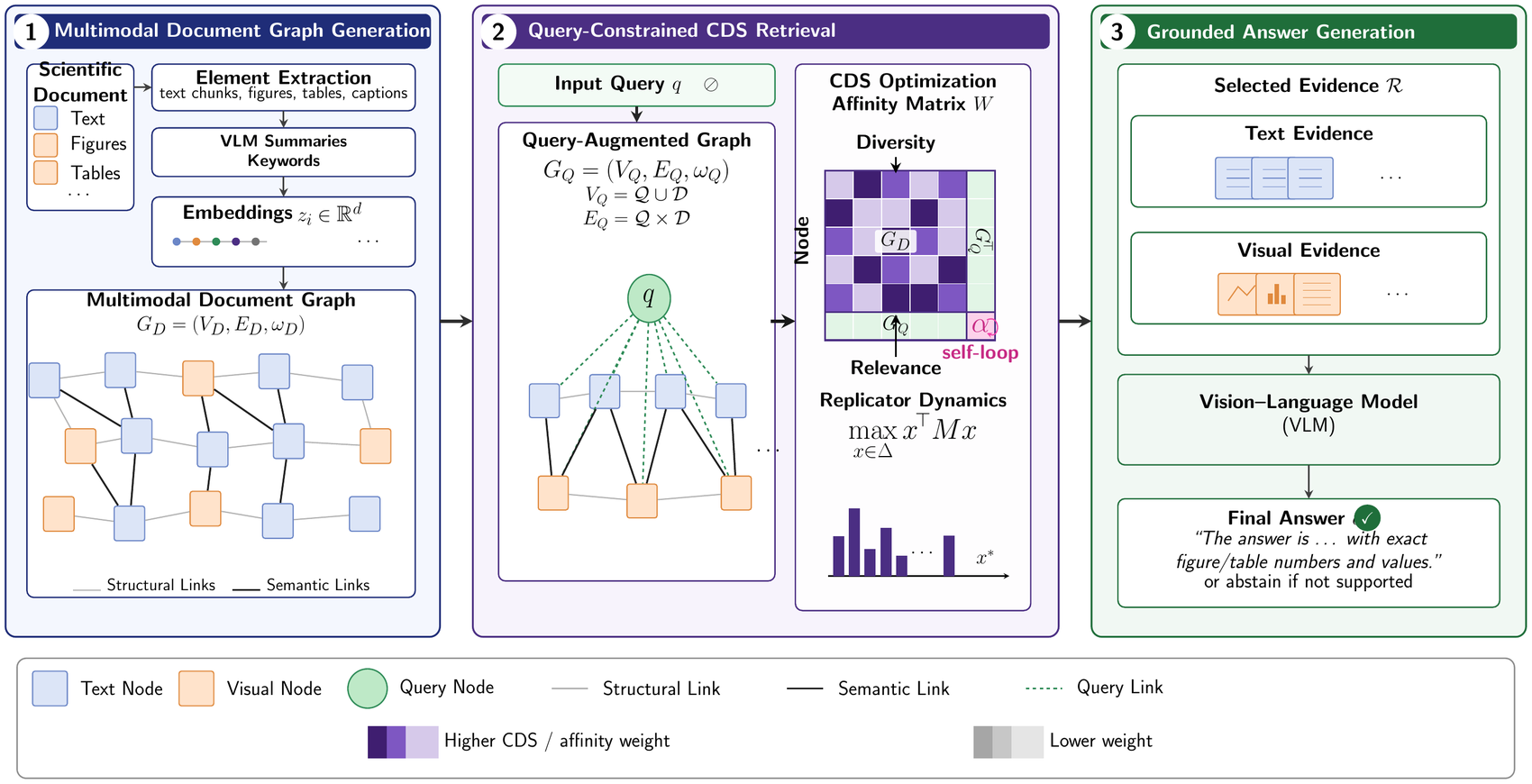
Three advantages over similarity ranking
Query-as-constraint
The query enters the constraint diagonal of the CDS objective, so query coherence emerges as an equilibrium property rather than from a tuned trade-off. The formulation extends to multi-query and pinned-memory settings unchanged.
Automatic relevance–diversity balance
A spectral bound fixes the balance between relevance and redundancy, removing the hand-tuned λ that MMR and DPP-MAP pipelines require.
Global equilibrium via replicator dynamics
Selection converges to a Nash equilibrium of a quality–diversity game, avoiding the order-dependent distortions of greedy heuristics. First application of constrained dominant sets to multimodal RAG.
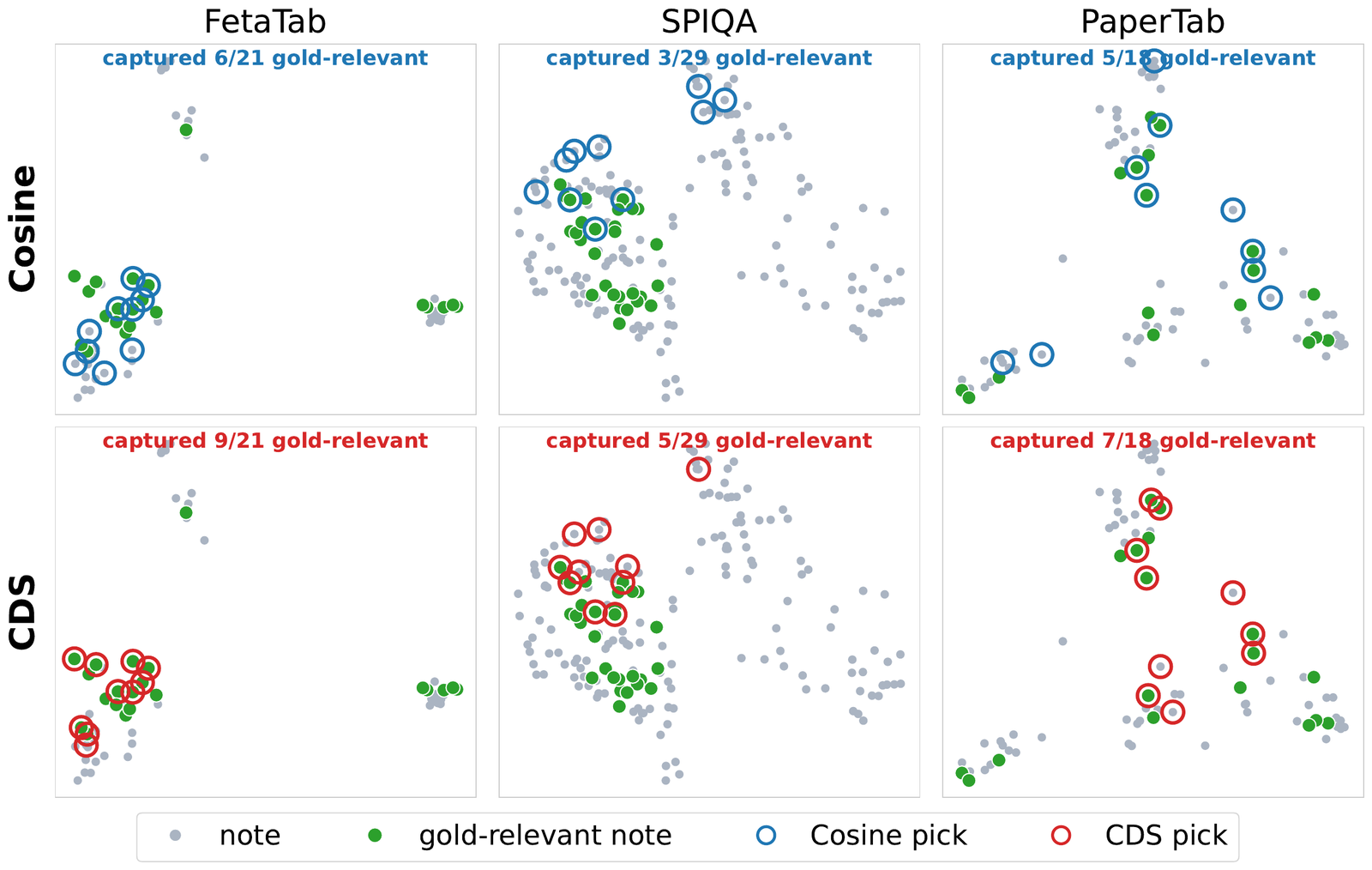
03 Results
Main results on the full VisDoMBench benchmark, averaged over three runs (± standard deviation). Bold = best per column, underline = second best. Our method uses the open encoder with a Qwen3-VL-32B reader.
| Model | SPIQA | FetaTab | PaperTab | SciGraphQA | SlideVQA | Average |
|---|---|---|---|---|---|---|
| GPT-5 | 55.22 | 63.94 | 37.08 | 64.08 | 45.06 | 53.08 |
| Qwen3-VL-32B | 29.86 | 37.39 | 34.32 | 23.06 | 24.87 | 29.90 |
| Deepseek-OCR | 63.60 | 70.32 | 51.58 | 61.91 | 65.69 | 62.62 |
| RAGAnything | 67.69 | 57.76 | 42.02 | 41.60 | 52.18 | 52.25 |
| MA-RAG | 45.52 | 27.70 | 33.43 | 29.32 | 29.40 | 33.07 |
| GraphRAG | 62.65 | 61.35 | 42.90 | 65.76 | 21.68 | 50.87 |
| LightRAG | 73.88 | 64.71 | 51.02 | 75.00 | 29.63 | 58.85 |
| MMGraphRAG | 69.91 | 72.40 | 56.36 | 64.11 | 54.20 | 63.40 |
| VisDoMRAG | 75.44 | 61.02 | 56.21 | 63.36 | 69.03 | 65.01 |
| ViDoRAG | 68.18 | 58.74 | 43.67 | 37.86 | 71.71 | 56.03 |
| G²-Reader | 73.19 | 66.89 | 57.10 | 61.56 | 72.31 | 66.21 |
| Qwen3-VL-32B + CDS | 78.85 | 70.90 | 65.59 | 57.45 | 62.17 | 66.99 |
CDS sets the best average and leads on SPIQA and PaperTab — the subsets where complementary evidence is fragmented and redundancy hurts most.
MMLongBench-Doc — retriever as a drop-in module
Adding CDS as a retriever lifts single-VLM baselines across model scales. Accuracy (%), mean ± std over 3 runs.
| Model | Params | Accuracy |
|---|---|---|
| Qwen3-VL-32B | 32B | 40.19 |
| Qwen3-VL-32B + CDS | 32B | 45.01 |
| Qwen2.5-VL-7B | 7B | 28.36 |
| Qwen2.5-VL-7B + CDS | 7B | 32.30 |
| GLM-4.1V | 9B | 41.04 |
| GLM-4.1V + CDS | 9B | 39.15 |
04 Contributions
- Query-as-constraint formulation. The query is incorporated into the constraint diagonal of the CDS objective, so query coherence emerges as an equilibrium property rather than from tuning. Generalises to multi-query and pinned-memory settings without modification.
- First application of constrained dominant sets to multimodal RAG. Instantiated on an agentic-memory-style note graph with note–note dissimilarity edges, query–note similarity edges, and replicator dynamics as the solver.
- State-of-the-art on VisDoMBench and competitive on MMLongBench-Doc. With a Qwen3-VL-32B reader, 66.99 average — outperforming G²-Reader, ViDoRAG, MMGraphRAG, LightRAG, RAG-Anything, and a standalone GPT-5.
§ Citation
@article{mehrish2026cds,
title = {Constrained Dominant Sets for Multimodal Document Question Answering},
author = {Mehrish, Ambuj and Vascon, Sebastiano},
journal = {arXiv preprint},
year = {2026},
url = {https://arxiv.org/abs/2606.07252}
}