§ Abstract
Long, multimodal documents force retrieval-augmented systems to assemble answers from evidence fragmented across text, tables, and slides — broken across cells in a long table, spread over multiple slides, or split between a figure and its discussion. Top-k chunk retrieval treats each fragment independently and cannot represent how evidence connects. We introduce FlowReader, which reframes evidence assembly as a min-cost flow problem on a multimodal node graph: a single scoring vector h controls source selection (via MMR), sink selection (via a length-aware answerability proxy), and the costs and capacities of every edge. The optimal flow is decomposed into candidate evidence paths; a compact non-redundant subset is selected by entropy-regularised replicator dynamics; and parallel VLM workers under a dual-process gate produce the answer with a single System-2 refinement pass triggered when answer consistency is low or routed flow is strained. On VisDoMBench, FlowReader is best on the two subsets dominated by fragmented evidence — PaperTab (58.40, +1.30 over G²-Reader) and SlideVQA (72.93, +0.62) — and competitive elsewhere. Macro-averaged across all five subsets, FlowReader (65.47) sits within 0.74 of the strongest baseline.
01 Fragmented evidence breaks top-k retrieval
The answer to a question about a long report is rarely contained in a single chunk. It is split between a figure and its discussion, spread over several slides, or scattered across the cells of a long table. Top-k chunk retrieval scores each fragment independently and has no way to represent how those fragments connect — so it either misses a piece of the chain or floods the reader with redundant near-duplicates.
FlowReader treats the problem as routing: how should a fixed budget of evidence flow from the most query-relevant sources to the most answerable sinks, through the cheapest coherent paths in the document graph?
02 Evidence assembly as min-cost flow
A single learned scoring vector h over graph nodes drives the entire pipeline: it selects sources via maximal marginal relevance, selects sinks via a length-aware answerability proxy, and parameterises the cost and capacity of every edge. Solving the resulting min-cost flow (OR-Tools, network simplex) gives an optimal routing of evidence, which is then decomposed into candidate paths.
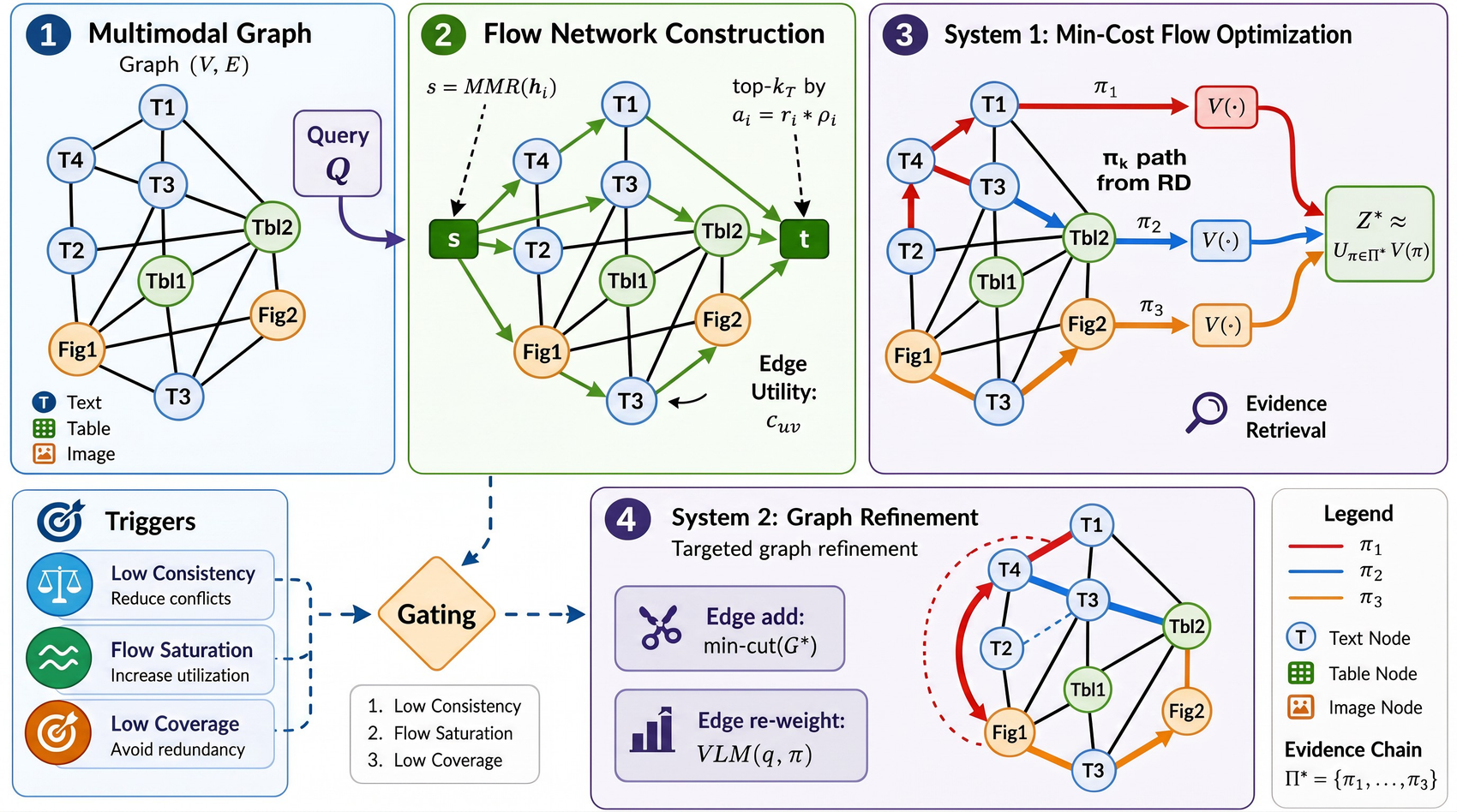
Unified scoring vector
A single vector h controls source selection, sink selection, and every edge cost and capacity — collapsing scoring, routing, and selection into one controllable object.
Min-cost flow routing
The optimal flow at demand F=6 is solved with OR-Tools and decomposed into up to 60 candidate evidence paths — capturing how fragmented evidence connects, which top-k cannot.
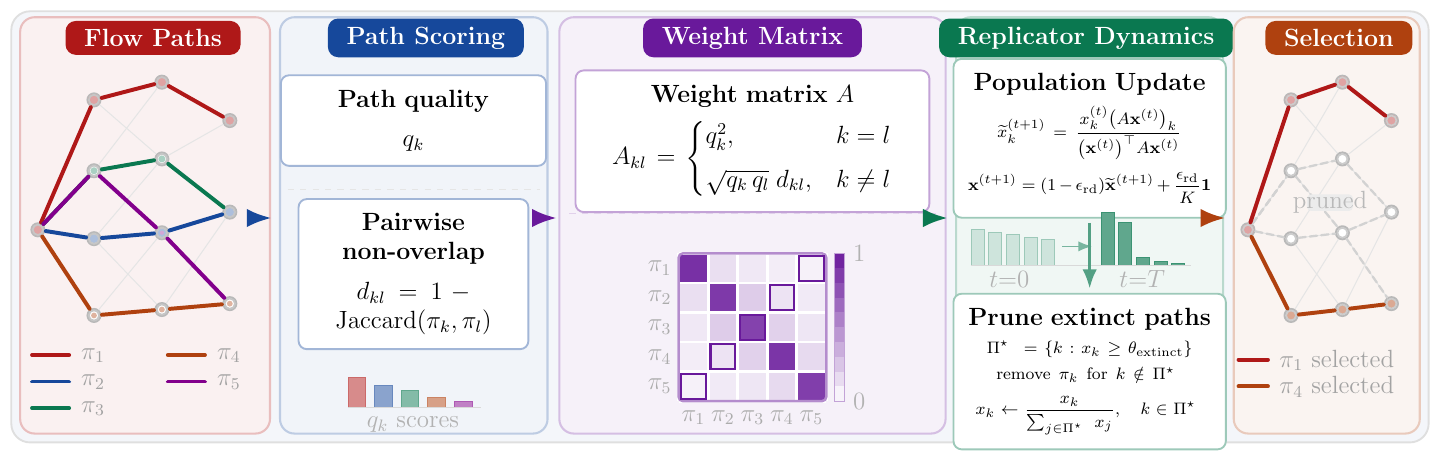
Entropy-regularised path selection
A compact, non-redundant subset of paths is selected by replicator dynamics with an entropy regulariser that prevents premature collapse onto a single route.
Dual-process System-2 gate
Parallel VLM workers answer in System 1. A single System-2 refinement pass fires only when answer consistency is low or routed flow is strained — bounding extra compute a priori.
Entropy-regularised replicator dynamics
Path selection is a quality–diversity game over the candidate paths. An entropy term smooths the trajectory and preserves exploration across plausible routes; the fixed point approximates a Nash equilibrium, after which low-mass paths are pruned.
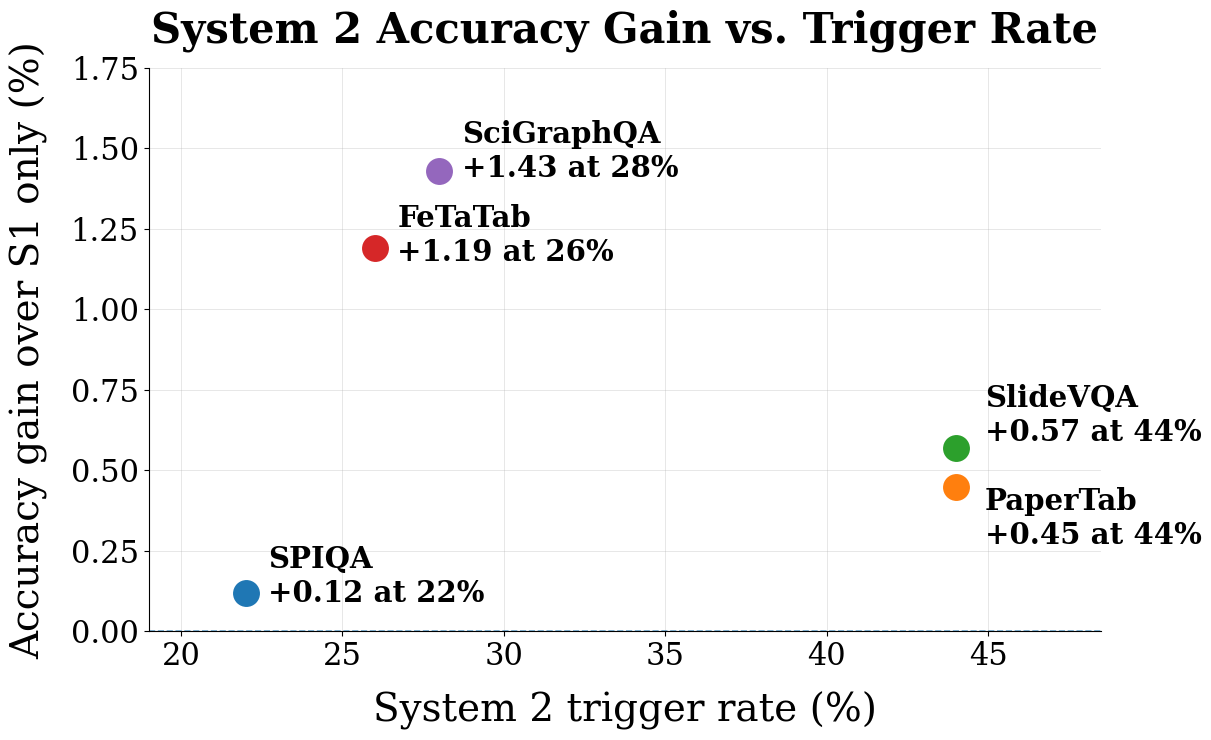
When System 2 fires
03 Results
Main results on the full VisDoMBench benchmark, averaged over three runs (± standard deviation). Bold = best per column, underline = second best.
| Model | Type | SPIQA | FetaTab | PaperTab | SciGraphQA | SlideVQA |
|---|---|---|---|---|---|---|
| GPT-5 | VLM | 55.22 | 63.94 | 37.08 | 64.08 | 45.06 |
| Qwen3-VL-32B | VLM | 29.86 | 37.39 | 34.32 | 23.06 | 24.87 |
| Deepseek-OCR | OCR | 63.60 | 70.32 | 51.58 | 61.91 | 65.69 |
| RAGAnything | RAG | 67.69 | 57.76 | 42.02 | 41.60 | 52.18 |
| MA-RAG | RAG | 45.52 | 27.70 | 33.43 | 29.32 | 29.40 |
| GraphRAG | Graph-RAG | 62.65 | 61.35 | 42.90 | 65.76 | 21.68 |
| LightRAG | Graph-RAG | 73.88 | 64.71 | 51.02 | 75.00 | 29.63 |
| MMGraphRAG | Graph-RAG | 69.91 | 72.40 | 56.36 | 64.11 | 54.20 |
| VisDoMRAG | Graph-RAG | 75.44 | 61.02 | 56.21 | 63.36 | 69.03 |
| ViDoRAG | Graph-RAG | 68.18 | 58.74 | 43.67 | 37.86 | 71.71 |
| G²-Reader | Graph-RAG | 73.19 | 66.89 | 57.10 | 61.56 | 72.31 |
| FlowReader | Ours | 74.23 | 64.45 | 58.40 | 57.32 | 72.93 |
| — w/o System 2 | Ablation | 74.11 | 63.26 | 57.95 | 55.89 | 72.36 |
FlowReader leads on PaperTab and SlideVQA — the subsets dominated by evidence fragmented across cells and slides, exactly where independent top-k scoring fails. The System-2 pass contributes a consistent lift across subsets.
04 Bounded, adaptive compute
Unlike iterative replanning loops that are unbounded in their replanning cap, FlowReader's cost has an a-priori bound: System-1 calls plus a single conditional System-2 budget. The gate spends extra compute only on the queries that need it.
Generator: Qwen3-VL-32B-Instruct (vLLM, tensor-parallel 4, bf16) on 4× A100 80GB. Embedder: nomic-embed-text-v1.5. Parser: MinerU. Flow solver: Google OR-Tools (network simplex). All hyperparameters fixed once on a 50-query dev split and reused unchanged.
§ Citation
@article{mehrish2026flowreader,
title = {FlowReader: Min-Cost Flow Optimization for Multi-Modal Long Document Q&A},
author = {Mehrish, Ambuj and Vascon, Sebastiano},
journal = {arXiv preprint},
year = {2026},
url = {https://arxiv.org/abs/2606.07235}
}